要通过Python爬取网站数据,您可以使用requests库获取网页内容,然后使用BeautifulSoup库解析HTML数据。下面是一个简单的示例,向您展示如何使用这两个库来爬取网站数据。 首先,确保您已经安装了requests和BeautifulSoup库。如果没有,请使用以下命令安装:
首先,确保您已经安装了requests和BeautifulSoup库。如果没有,请使用以下命令安装:
bash
代码
pip install requests
pip install beautifulsoup4
然后,您可以编写一个简单的Python脚本来爬取网站数据:
python
代码
import requests
from bs4 import BeautifulSoup
# 设置目标URL
url = "https://example.com"
# 发送HTTP请求并获取响应内容
response = requests.get(url)
# 检查请求是否成功(状态码为200表示成功)
if response.status_code == 200:
# 将响应内容解析为BeautifulSoup对象
soup = BeautifulSoup(response.text, "html.parser")
# 使用BeautifulSoup的方法查找特定的HTML元素
# 例如:查找所有的段落标签<p>
paragraphs = soup.find_all("p")
# 循环遍历所有找到的段落标签并打印内容
for p in paragraphs:
print(p.get_text())
else:
print(f"请求失败,状态码:{response.status_code}")
在这个例子中,我们首先导入requests和BeautifulSoup库,然后设置要爬取的目标URL。接着,我们使用requests.get()函数发送HTTP请求并获取响应内容。我们检查响应的状态码是否为200,表示请求成功。
如果请求成功,我们将响应的文本内容传递给BeautifulSoup构造函数,创建一个BeautifulSoup对象。然后,我们可以使用BeautifulSoup对象的方法(如find_all())来查找特定的HTML元素。在这个示例中,我们查找了所有的段落标签<p>。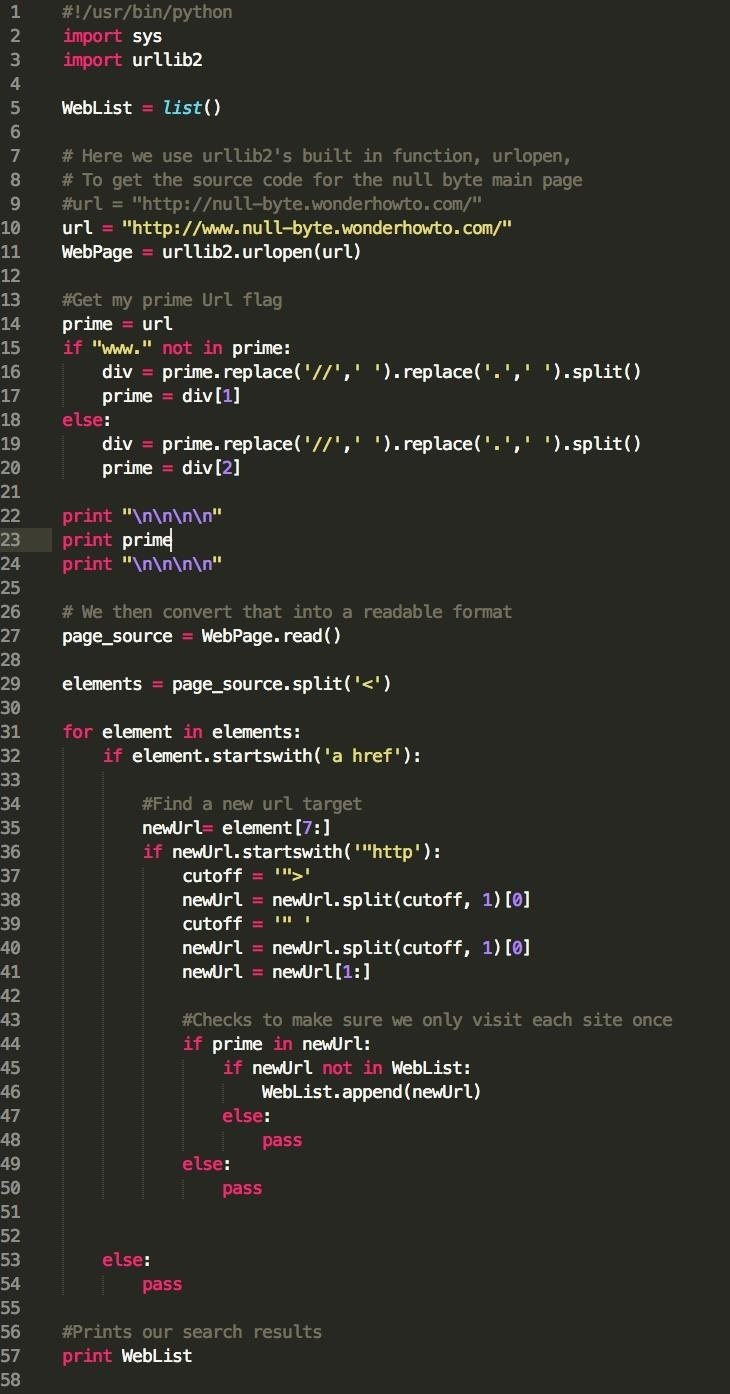 最后,我们遍历所有找到的段落标签并使用get_text()方法打印其内容。
最后,我们遍历所有找到的段落标签并使用get_text()方法打印其内容。
下面是一个稍微复杂一点的例子,展示如何爬取一个包含新闻文章的网站。我们将继续使用requests和BeautifulSoup库。
python
代码
import requests
from bs4 import BeautifulSoup
# 设置目标URL
url = "https://news.example.com"
# 发送HTTP请求并获取响应内容
response = requests.get(url)
# 检查请求是否成功(状态码为200表示成功)
if response.status_code == 200:
# 将响应内容解析为BeautifulSoup对象
soup = BeautifulSoup(response.text, "html.parser")
# 使用BeautifulSoup的方法查找特定的HTML元素
# 例如:查找所有的新闻标题所在的div元素
article_divs = soup.find_all("div", class_="article-title")
# 循环遍历所有找到的div元素并打印标题和链接
for div in article_divs:
title = div.find("h2").get_text()
link = div.find("a")["href"]
print(f"标题:{title}\n链接:{link}\n")
else:
print(f"请求失败,状态码:{response.status_code}")
在这个示例中,我们首先导入requests和BeautifulSoup库,然后设置要爬取的目标URL。接着,我们使用requests.get()函数发送HTTP请求并获取响应内容。我们检查响应的状态码是否为200,表示请求成功。
如果请求成功,我们将响应的文本内容传递给BeautifulSoup构造函数,创建一个BeautifulSoup对象。然后,我们使用BeautifulSoup对象的方法(如find_all())来查找特定的HTML元素。在这个示例中,我们查找了所有包含新闻标题的<div>元素。
接下来,我们遍历所有找到的<div>元素。对于每个<div>,我们使用find()方法来查找标题(<h2>)和链接(<a>)。然后,我们使用get_text()方法获取标题文本,并使用字典访问语法获取链接的href属性。最后,我们打印新闻标题和链接。 这只是一个简单的例子,实际上,您可能需要处理更复杂的HTML结构和不同类型的数据。但这个示例应该足够让您开始使用Python爬取网站数据。在实际应用中,您可能还需要处理各种错误和异常,以确保您的爬虫更加健壮和可靠。
这只是一个简单的例子,实际上,您可能需要处理更复杂的HTML结构和不同类型的数据。但这个示例应该足够让您开始使用Python爬取网站数据。在实际应用中,您可能还需要处理各种错误和异常,以确保您的爬虫更加健壮和可靠。




声明本文内容来自网络,若涉及侵权,请联系我们删除! 投稿需知:请以word形式发送至邮箱18067275213@163.com
做好用户体验就好
开博容易,但写出高质量的文章就难了,这是很多人欠缺的。
很好哦,自己的网站301还没有做好
好像也可以这样说呢
Google10秒钟就能完成索引库更新,太N了